
Who uses frequently Chatgpt He knows it well: the answers he gives us are not always correct. It often happens that the model, in a safe tone, give information who sound plausible but in reality they are wrong. In the world of artificial intelligence this phenomenon is called hallucinationand concerns all language models (not only chatgpt, but also Claude, Gemini, Deepseek and others).
For some time, academic research has been trying to understand why it happens and how to reduce the problem. At the beginning of September 2025, Openai published an analysis in which he tries to explain the main causes of hallucinations and to propose some solutions.
According to the study, part of the problem depends on the way the models are evaluated during training. Today, in fact, a model is “rewarded” if it tries to guess an answer, even when it is not certain that it is correct. So learn that it is better to invent something rather than admiting that you don’t know. By changing this approach, hallucinations could decrease and systems become more reliable.
Let’s see in more detail what hallucinations are, what Openai has discovered and what consequences it is bringing.
What are chatgpt hallucinations
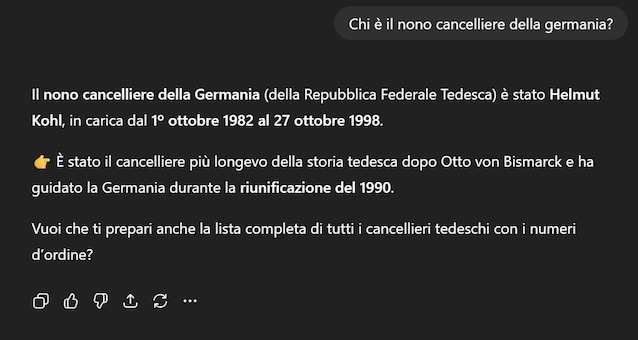
In the context of artificial intelligence, A hallucination is a response that seems correct But in reality it is invented or without foundation. For example, we asked Chatgpt: “Who is Germany’s ninth chancellor?”. In three different attempts, from different accounts and at different times of the day, the model replied: Willy Brandt, Helmut Kohl and Olaf Scholz. Only the latter is correct: the other two responses were hallucinations.
Hallucinations are born because the language models have been designed to generate coherent and natural text, not to replace a search engine or provide perfectly accurate data.
Because hallucinations take place and how to try to mitigate them: the study
In his article “Why Language Models Halucinated” (“Because the language models have hallucinations”), Openai explains that the problem derives from way in which the models are trained And evaluated: to now, a model has been considered “better” if it gave more correct answers. Consequently, language models (LLM) they are trained to try to give an answer, even invented, instead of admitting not to know. The authors compare this mechanism to that of unprepared students in front of a cross -check verification: if they do not know the answer, they prefer to guess instead of leaving the box empty, because in this way they still have a chance to earn points.
Then there are two other causes that lead the LLM to make mistakes:
- The quality of the data: If in the texts used for training there are errors, the model will repeat them in the answers. It is the principle of “Garbage in, Garbage Out”: if I enter garbage (incorrect data), I will get garbage (wrong answers).
- The limits of knowledge: Even if the data did not contain any mistakes, they could not however cover all the knowledge of human knowledge and responses. Some questions will not answer the data, and the model, having learned that “it is better to say something than admitting ignorance”, will end up inventing.
These ideas are not entirely new in the field of research on hallucinations, the novelty introduced by Openai is the idea of changing the way we evaluate the answers: penalize much more the errors And reward honesty of the “I don’t know”. In this way we aim to create more “humble” models, thus mitigating the problem of hallucinations.
What is being done to solve the problem
Even before this research, the companies had experienced some solutions to reduce hallucinations. One of the most common is theuse of external sources in real time, like the Web searches. This technique reduces hallucinations, even if it does not completely eliminate them.
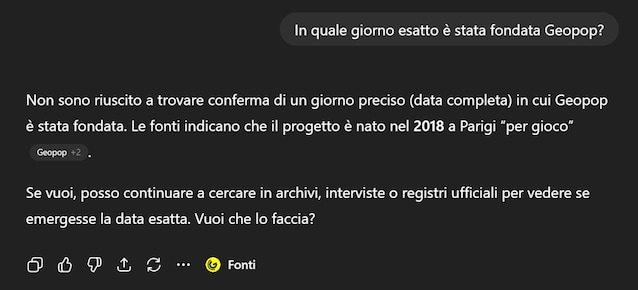
With the arrival of GPT-5, progress has become more evident. Today, in the face of too specific questions, such as “On what exact day was Geopop founded?”, The model admits that he does not know the answer, which is unthinkable with the previous versions.
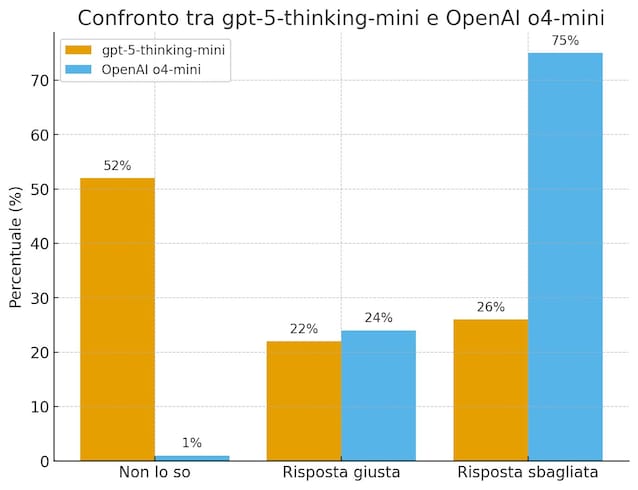
According to the data of Openai, when they tested the new model GPT-5-Thinking-Mini (the “smaller” and less powerful version of GPT-5) on a dataset created on purpose to measure the ability to make fact-checking, admitted to don’t know In 52% of cases (against 1% of the previous version) and committed Less errors (26% against 75%). The percentage of exact answers was slightly lower (22% against 24%), but the overall quality has improved: better a model that admits its limits, rather than one who is wrongly wrong.
Another research front on which Openai is working concerns the language with which the AI communicates uncertainty. In our initial example, it would have been very different if Chatgpt replied: “Maybe the ninth chancellor could be Kohl” instead of giving us the wrong answer with great safety. Such a response would have made it more evident that it was not a certain fact.
However, a very big problem remains open: plus the answers I am long And structuredmore increase The risk Of hallucinations. This problem is much more difficult to solve and the solution proposed by Openai is not enough. This study, however, is a positive sign in the right direction: it is clear that Openii is working to get a more reliable AI. And in the meantime, we users can continue to use it with a critical spirit, always checking the answers we get.